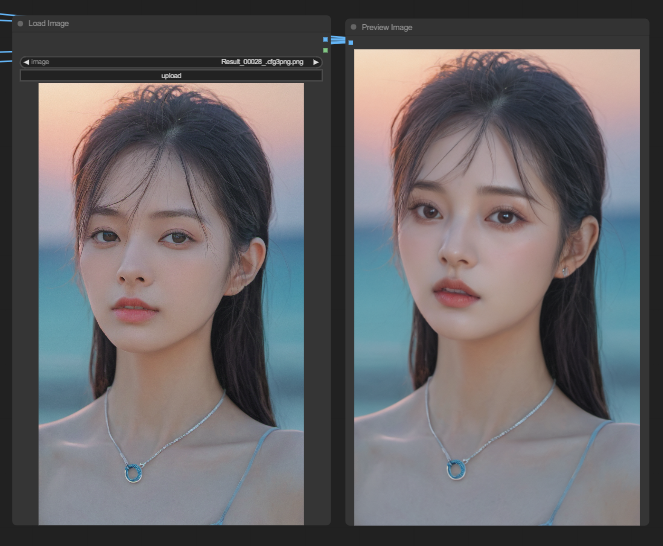
스테이블 디퓨전에서 이미지 생성을 할 때 더 정밀하게 제어해줄 도구가 바로 오늘 소개할 ControlNet 입니다.
ControlNet을 심층적으로 다루면서 ControlNet이 무엇인지, 어떤 역할을 하고 어떻게 사용하는지에 대해 자세히 알아보겠습니다.
ControlNet이란 무엇인가
ControlNet은 Text-to-image 모델의 기능을 크게 향상시켜 이미지 생성 시 전례 없는 공간 제어를 가능하게 하는 혁신적인 기술이라고 할 수 있습니다.
신경망 아키텍처인 ControlNet은 Stable Diffusion과 같은 사전 학습된 대규모 모델과 원활하게 통합됩니다. 수십억 개의 이미지를 기반으로 구축된 이러한 모델의 광범위한 학습을 활용하여 이미지 생성 프로세스에 공간 조건을 도입합니다.
이러한 조건은 이미지의 가장자리와 사람의 포즈부터 깊이 등 다양하며, 이전에 텍스트 프롬프트만으로는 불가능했던 방식들을 가능하게 해주는 역할을 합니다.
ControlNet 작동 방식
컨트롤넷의 작동 방식은 독특한 방법론에 있습니다. 처음에는 원래 모델의 파라미터를 보호하여 기본 훈련이 변경되지 않도록 합니다. 그 후, ControlNet은 "zero convolutions"을 활용하여 훈련용 모델 인코딩 레이어의 복제본을 도입합니다.
특별히 설계된 이 컨볼루션 레이어는 가중치가 0인 상태에서 시작하여 새로운 공간 조건을 신중하게 통합합니다. 이 접근 방식은 방해가 되는 노이즈가 개입하는 것을 방지하여 모델의 원래 숙련도를 유지하면서 새로운 학습을 시작합니다.
이러한 이론은 조금 어려울 수 있기에 Node들을 뜯어보며 알아보겠습니다.
ControlNet Basic WorkFlow
기본적인 ControlNet 워크플로우의 모습을 먼저 보여드리고 필수 node들과 Open Pose, Tile, Cnay 같은 preprocessor(전처리기)에 관해 설명드리겠습니다.
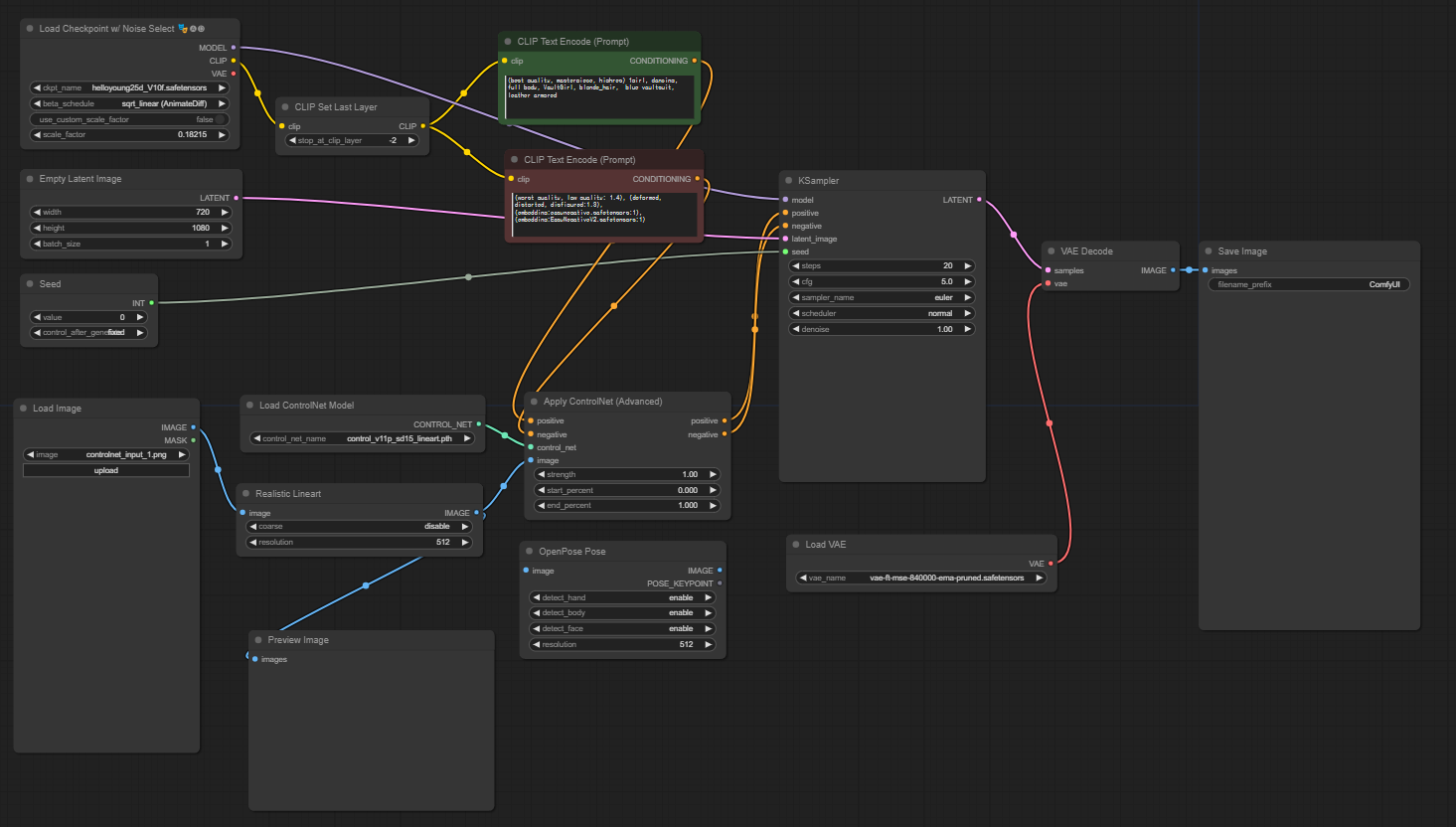
Apply ControlNet
이 단계에서는 컨트롤넷을 ComfyUI 워크플로우에 통합하여 이미지 생성 프로세스에 추가적인 컨디셔닝을 적용할 수 있습니다. 텍스트 프롬프트와 함께 시각적 안내를 적용할 수 있게 해주는 역할을 하며, 최정적으로 ControlNet을 적용시켜 줄 node 입니다.
Apply ControlNet node의 input 엣지
- positive & negative : 기본적으로 생성된 이미지에서 원하는 결과와 피해야 할 측면을 정하는 데 매우 중요한 역할을 합니다. Clip text Enconde에서 지정한 각각의 컨디셔닝에 맞춰서 'Positive Prompt'와 'Negative Prompt'에 연결해야 합니다.
- control_net : "Load ControlNet model" 노드의 출력에 연결해야 합니다.이 단계에선 컨트롤넷 또는 T2IAdaptor 모델을 선택하고 워크플로에 통합하여 diffusion model이 선택한 모델에서 제공하는 특정 지침의 이점을 누릴 수 있도록 하는 데 필수적입니다. 컨트롤넷이든 T2IAdaptor이든 각 모델은 특정 데이터 유형이나 스타일 선호도에 따라 이미지 생성 프로세스에 영향을 미치도록 엄격하게 훈련됩니다.
- image : 사용 중인 ControlNet model의 특정 요구 사항을 충족하도록 이미지를 조정하는 데 중요한 "ControlNet preprocessor"노드에 연결해야 합니다.
선택한 ControlNet 모델에 맞는 올바른 preprocessor(전처리기)를 사용하는 것이 중요합니다. 이 단계에서는 원본 이미지에 형식, 크기, 색상 조정 또는 특정 필터 적용 등 필요한 수정을 수행하여 ControlNet의 가이드라인에 맞게 최적화합니다. 이 전처리 단계가 끝나면 원본 이미지가 수정된 버전으로 대체되고, ControlNet에서 이를 활용합니다.
Apply ControlNet node의 output 엣지
- positive & negative : 컨트롤넷의 미묘한 효과와 시각적 안내가 담긴 이 출력은 ComfyUI에서 동작을 조정하는 데 중추적인 역할을 합니다.
그 다음에는 샘플링 단계를 위해 KSampler로 진행하여 생성된 이미지를 더욱 다듬습니다.
더 높은 수준의 디테일과 커스터마이징을 원하는 경우 계속해서 컨트롤넷을 추가 레이어링할 수 있습니다.
Apply ControlNet node의 파라미터
- strength :ComfyUI에서 생성된 이미지에 대한 컨트롤넷의 효과 강도를 결정합니다. 값이 1.0이면 최대 강도를 의미하며, 이는 컨트롤넷의 안내가 확산 모델의 출력에 최대 영향을 미친다는 것을 의미합니다. 반대로 0.0 값은 영향력이 없음을 나타내며, 이미지 생성 프로세스에 대한 컨트롤넷의 효과를 비활성화합니다.
- start_percent :컨트롤넷이 생성에 영향을 미치기 시작하는 시작 지점을 확산 프로세스의 백분율로 지정합니다. 예를 들어 시작 퍼센트를 20%로 설정하면 확산 프로세스의 20% 지점부터 컨트롤넷의 안내가 이미지 생성에 영향을 미치기 시작합니다.
- end_percent :' start_percent '와 유사하게 'end_percen'파라미터는 컨트롤넷의 영향력이 중단되는 지점을 정의합니다.예를 들어, end_percent가 80%이면 확산 프로세스의 80% 완료 시점에서 컨트롤넷의 안내가 이미지 생성에 영향을 미치지 않는 걸 의미합니다, 최종 단계에는 영향을 미치지 않는다는 의미죠

ControlNet - Open Pose
- Openpose(=Openpose=body) : 눈, 코, 목, 어깨, 팔꿈치, 손목, 무릎, 발목과 같은 기본적인 신체 키포인트를 식별하는 컨트롤넷의 기본 모델입니다. 기본적인 인체 포즈 복제에 이상적입니다.
- Openpose_face : 얼굴 키포인트 감지를 추가하여 OpenPose 모델을 확장하여 얼굴 표정과 방향에 대한 더 자세한 분석을 제공합니다. 이 컨트롤넷 모델은 얼굴 표정에 중점을 둔 프로젝트에 필수적입니다.
- Openpose_hand : 세부적인 손 제스처와 위치에 초점을 맞춰 손과 손가락의 복잡한 디테일을 캡처할 수 있는 기능으로 OpenPose 모델을 강화합니다. 이 기능의 추가를 통해 ControlNet 내에서 OpenPose의 활용성이 향상됩니다.
- Openpose_faceonly : 표정과 얼굴 방향 캡처에 집중하기 위해 신체 키포인트를 생략하고 얼굴 디테일에만 특화된 모델입니다. 컨트롤넷 내 이 모델은 얼굴 특징에만 집중합니다.
- Openpose_full : 오픈포즈, 오픈포즈_페이스, 오픈포즈_핸드 모델을 포괄적으로 통합하여 전신, 얼굴, 손을 완벽하게 감지하여 컨트롤넷 내에서 사람의 전체 포즈를 복제할 수 있습니다.
- DW_Openpose_full : 더욱 세밀하고 정확한 포즈 감지를 위해 추가적인 개선 사항을 통합한 OpenPose_full 모델의 향상된 버전입니다. 이 버전은 컨트롤넷 프레임워크 내에서 포즈 감지 정확도의 정점에 해당하는 버전입니다.
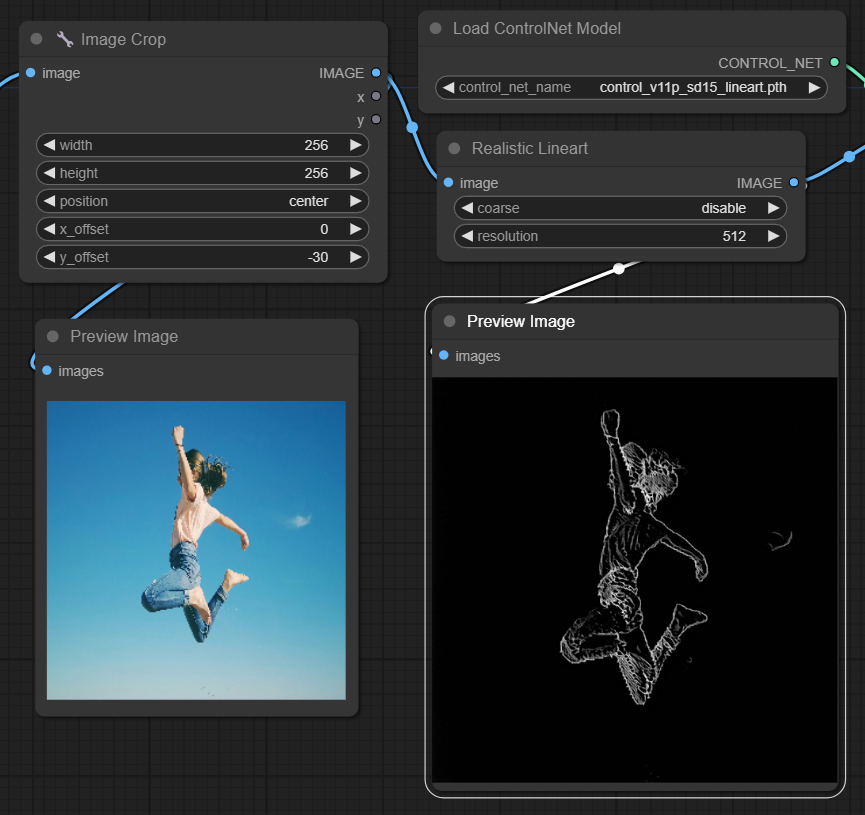
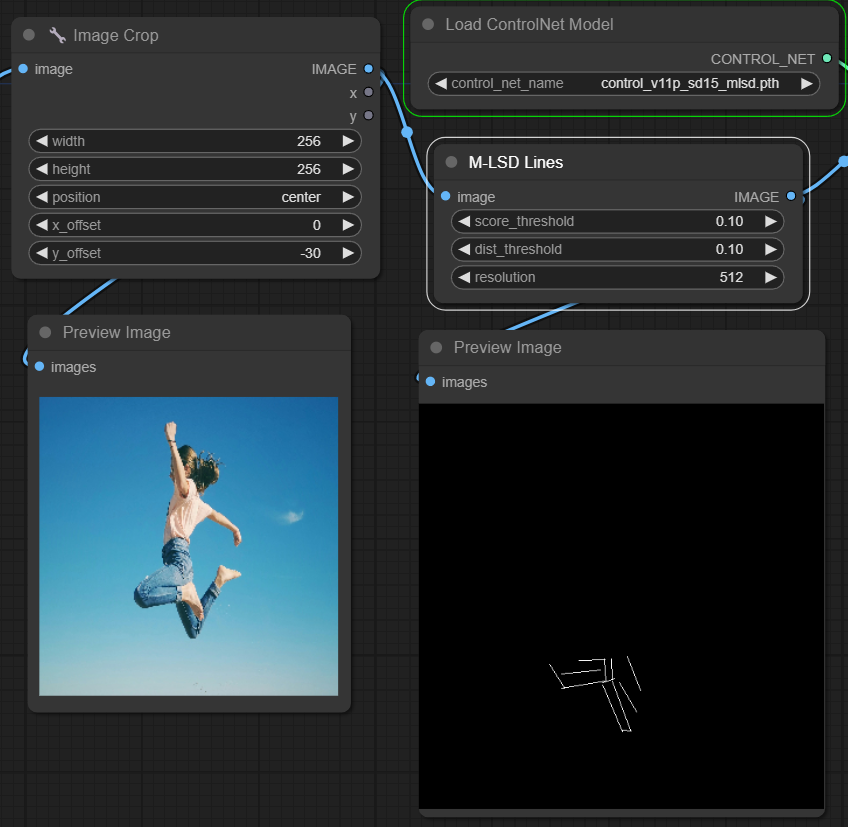
(저는 현재 Loda image에서 불러온 이미지의 사이즈가 커서 자체적으로 Image Crop node를 통해 이미지를 잘라줬습니다. 참조 이미지의 사이즈가 클 경우 인식이 잘 안되기 때문에 처음부터 사이즈가 작은 이미지를 불러오거나, 이렇게 ComfyUI에서 자체적으로 잘라줘야합니다.)

ControlNet - Tile
Tile 리샘플 모델은 이미지의 디테일을 향상시키는 데 사용됩니다. 특히 업스케일러와 함께 이미지 해상도를 향상시키면서 더 세밀한 디테일을 추가하는 데 유용하며, 이미지 내의 텍스처와 요소를 선명하게 하고 풍부하게 하는 데 자주 사용됩니다.

ControlNet - Canny
Canny 모델은 이미지의 다양한 가장자리를 감지하는 다단계 프로세스인 Canny edge detection 알고리즘을 적용합니다. 이 모델은 이미지의 시각적 구성을 단순화하면서 이미지의 구조적 측면을 보존하는 데 유용하며, 양식화된 아트 또는 추가 이미지 조작 전 사전 처리에 유용합니다.

ControlNet - Depth
깊이 모델은 2D 이미지에서 깊이 정보를 추론하여 인식된 거리를 그레이스케일 깊이 맵으로 변환합니다. 각 변형은 디테일 캡처와 배경 강조 사이에 서로 다른 균형을 제공합니다.
- Depth Midas : 디테일과 배경 렌더링의 균형을 맞추는 고전적인 깊이 추정 기능을 제공합니다.
- Depth Leres : 배경 요소를 더 많이 포함하는 경향으로 디테일을 향상시키는 데 중점을 둡니다.
- Depth Leres++ : 깊이 정보를 위한 고급 수준의 디테일을 제공하여 복잡한 장면에 이상적입니다.
- Zoe : 디테일 수준 측면에서 Midas 모델과 Leres 모델 간의 균형을 맞춥니다
- Depth Anything :다양한 장면을 위해 설계된 깊이 추정용 새롭고 개선된 모델입니다.
- Depth Hand Refiner : Depth map에서 손의 디테일을 개선하기 위해 특별히 설계되어 손의 위치가 중요한 장면에 유용합니다.

ControlNet - Lineart
Lineart 모델은 이미지를 양식화된 선 그림으로 변환하여 예술적 표현이나 추가 창작 작업의 기초로 유용하게 사용할 수 있습니다
- Lineart : 이 표준 모델은 이미지를 양식화된 선 드로잉으로 변환하여 다양한 예술적 또는 창의적인 프로젝트를 위한 다용도 기반을 제공합니다.
- Lineart anime :깔끔하고 정밀한 선이 특징인 애니메이션 스타일의 선화를 생성하는 데 중점을 두어 애니메이션 미학을 지향하는 프로젝트에 적합합니다.
- Lineart realistic : 보다 사실적인 터치로 선화를 그려 피사체의 본질을 더욱 세밀하게 포착할 수 있어 생생한 표현이 필요한 프로젝트에 적합합니다.
- Lineart coarse : 더 무겁고 굵은 선으로 선묘를 더욱 뚜렷하게 표현하여 눈에 띄는 인상적인 효과를 내며 특히 대담한 예술적 표현에 적합합니다.
ControlNet - Scribbles
Scribble 모델은 이미지를 낙서와 같은 모양으로 변형하여 손으로 그린 스케치처럼 보이도록 설계되었습니다. 특히 예술적인 스타일링이나 대규모 디자인 워크플로우의 예비 단계에 유용합니다.
- Scribble : 이미지를 손으로 그린 낙서나 스케치와 같은 디테일한 작품으로 변환하도록 설계되었습니다.
- Scribble HED : 전체적으로 중첩된 가장자리 감지(HED)를 활용하여 손으로 그린 스케치와 유사한 윤곽선을 만듭니다. 이미지를 다시 채색하고 스타일을 변경하여 아트웍에 독특한 예술적 감각을 더하는 데 권장됩니다.
- Scribble Pidinet : 픽셀 차이를 감지하는 데 중점을 두어 디테일을 줄이면서 깔끔한 선을 표현하므로 보다 선명하고 추상적인 표현에 이상적입니다.Scribble Pidinet은 선명한 곡선과 직선 가장자리를 원하는 사람들에게 적합하며, 필수적인 디테일을 유지하면서 세련된 느낌을 줍니다.
- Scribble xdog : 가장자리 감지를 위해 확장된 가우시안 차이(xDoG) 방법을 사용합니다. 이를 통해 임계값 설정을 조정하여 Scribble 효과를 미세 조정할 수 있으므로 아트웍의 디테일 수준을 제어할 수 있습니다. xDoG는 다용도로 사용할 수 있어 사용자가 예술 작품에서 완벽한 균형을 맞출 수 있습니다.

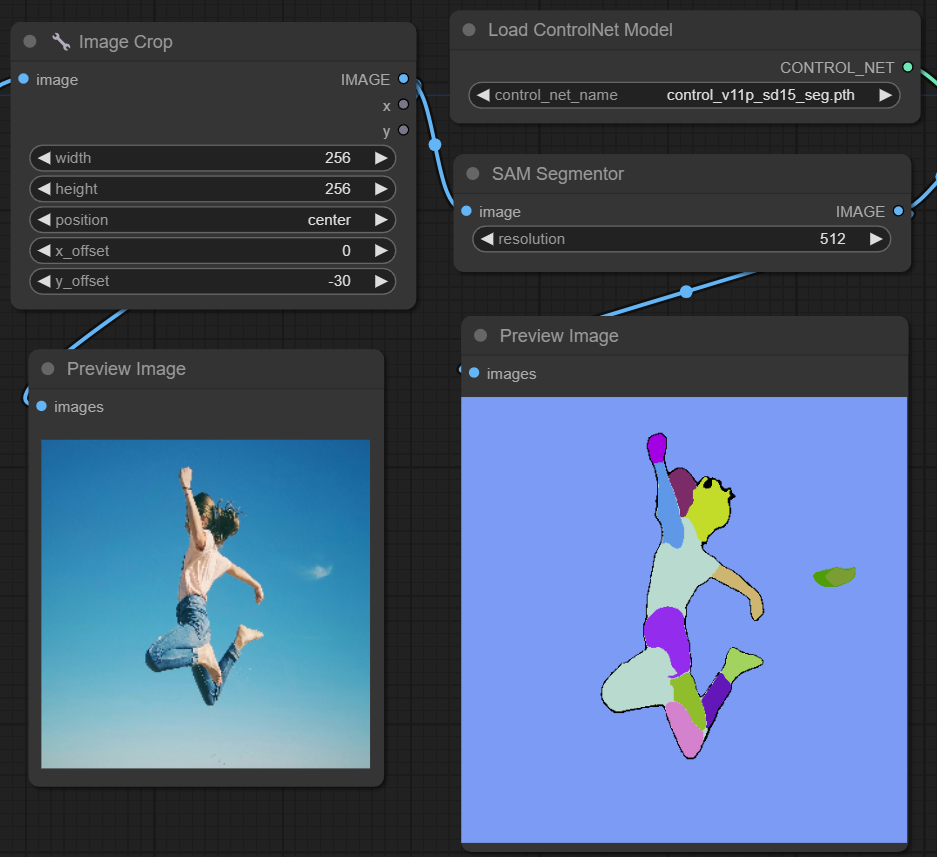
ControlNet - Segmentation
segmentation모델은 이미지 픽셀을 각각 특정 색상으로 표시되는 별개의 개체 클래스로 분류합니다. 이는 전경과 배경을 분리하거나 세부 편집을 위해 개체를 구분하는 등 이미지 내의 개별 요소를 식별하고 조작하는 데 매우 유용합니다.
- seg :이미지 내의 개체를 색상별로 구분하도록 설계되어 이러한 구분을 출력물에서 뚜렷한 요소로 효과적으로 변환합니다. 예를 들어, 방 레이아웃에서 가구를 구분할 수 있어 이미지 구성 및 편집을 정밀하게 제어해야 하는 프로젝트에 특히 유용합니다.
- ufade20k :ADE20K 데이터 세트에서 학습된 UniFormer segmentation 모델을 활용하여 다양한 개체 유형을 높은 정확도로 구분할 수 있습니다.
- ofade20k :ADE20K에서 학습된 OneFomer segmentation 모델을 사용하여 고유한 세분화 기능으로 객체 차별화에 대한 대안적인 접근 방식을 제공합니다.
- ofcoco :COCO 데이터 세트에 대해 학습된 OneFormer 세그먼테이션을 활용하여 COCO 데이터 세트의 매개변수 내에서 객체가 분류된 이미지에 맞게 조정되어 정확한 객체 식별 및 조작을 용이하게 합니다.
ControlNet - Shuffle
Shuffle 모델은 구성을 변경하지 않고 색 구성표나 텍스처와 같은 입력 이미지의 속성을 무작위로 변경하는 새로운 접근 방식을 도입합니다.
이 모델은 창의적인 탐색과 구조적 무결성은 유지하되 시각적 미학은 변경된 이미지의 변형을 생성하는 데 특히 효과적입니다. 무작위로 생성되므로 생성 프로세스에 사용된 시드 값의 영향을 받아 각 결과물이 고유합니다.

ControlNet - MLSD
M-LSD(모바일 라인 세그먼트 감지)는 직선을 감지하는 데 중점을 두어 건축 요소, 인테리어, 기하학적 형태가 강한 이미지에 이상적입니다. 장면을 구조적 본질로 단순화하여 인공 환경과 관련된 창의적인 프로젝트를 용이하게 합니다.
ControlNet - Normalmaps
Normalmaps을 사용하면 컬러 데이터에만 의존하지 않고 시각적 장면에서 표면의 방향을 모델링하여 복잡한 조명 및 텍스처 효과를 시뮬레이션할 수 있으며, 이는 3D 모델링 및 시뮬레이션 작업에 매우 중요합니다.
- Normal Bae : 이 방법은 정규 불확실성 접근법을 활용하여 Normalmap을 생성합니다. 표면의 방향을 묘사하는 혁신적인 기술을 제공하여 기존의 컬러 기반 방식이 아닌 모델링된 씬의 물리적 지오메트리를 기반으로 조명 효과의 시뮬레이션을 향상시킵니다.
- Normal Midas : Normal Midas 는 Midas 모델에서 생성된 뎁스 맵을 활용하여 노멀 맵을 정확하게 추정합니다. 이 접근 방식을 사용하면 씬의 깊이 정보를 기반으로 표면 텍스처와 조명을 미묘하게 시뮬레이션할 수 있으므로 3D 모델의 시각적 복잡성을 더욱 풍부하게 만들 수 있습니다.

ControlNet - Soft Edge
ControlNet Soft Edge는 디테일 제어와 자연스러운 외관에 중점을 두고 가장자리가 부드러운 이미지를 생성하도록 설계되었습니다.
고급 신경망 기술을 사용하여 정밀한 이미지 조작이 가능하며, 더 큰 창의적 자유와 원활한 블렌딩 기능을 제공합니다.
장단점을 고려할 때 기본적으로 SoftEdge_PIDI를 사용하는 것이 좋습니다. 대부분의 경우 매우 잘 작동합니다.

ControlNet - IP2P
ControlNet - IP2P(Instruct Pix2Pix) 모델은 이미지 변환을 위해Instruct Pix2Pix 데이터 세트를 활용하도록 맞춤화된 컨트롤넷 프레임워크 내의 고유한 변형입니다. 이 컨트롤넷 변형은 훈련 단계에서 명령 프롬프트와 설명 프롬프트 사이의 균형을 유지함으로써 차별화됩니다. 공식 Instruct Pix2Pix의 기존 접근 방식과 달리 ControlNet IP2P는 이러한 프롬프트 유형을 50 대 50으로 혼합하여 원하는 결과를 생성하는 데 있어 다양성과 효율성을 향상시킵니다.

이상으로 ComfyUI에서 ControlNet에 대해 심층적으로 다뤄봤습니다. 이제 이 ControlNet을 이용해 이미지를 생성할 때 더 다양한 방식으로 이미지를 제어할 수 있게 됐습니다.
다음 포스팅에서는 ControlNet을 이용한 워크플로우를 뜯어보며 실전에서 어떻게 작동시키며 응용하는지 알아보도록 하겠습니다.
'ComfyUI > Workflow 뜯어보기' 카테고리의 다른 글
| ComfyUI FreeU 기능을 이용하면 이미지 퀄리티가 달라집니다 (0) | 2024.05.29 |
|---|---|
| AI가 그린 어색한 손들 ComfyUI로 고쳐보기(feat.MeshGraphormer) (2) | 2024.05.22 |
| ComfyUI Face Detailer을 이용한 얼굴 보정 워크플로우 (0) | 2024.05.15 |
| ComfyUI Face Detailer 파라미터 뜯어보기 (feat.Impact Pack) (0) | 2024.05.09 |
| ComfyUI 인페인트(Inpaint)로 원하는 부분 수정하기 (0) | 2024.04.29 |
생성형 이미지 AI 중 스테이블 디퓨전에 관한 내용을 주로 다룹니다.
포스팅이 좋았다면 "좋아요❤️" 또는 "구독👍🏻" 해주세요!