

이번 포스팅은 스테이블 디퓨전에 관한 조금 전문적인 내용을 다뤄 볼까합니다.
이미지 생성 AI를 접하시는 분들은 보통 최대한 빠르고 간편하게 이미지를 생성하고 싶어하실 겁니다. AI가 내가 원하는 그림을 그냥 알아서 딱 만들어 줬으면 하죠, 그래서 그것들의 작동원리에 대해서는 관심이 없으신 분들이 대부분이고 저 또한 그랬습니다.
하지만 우리가 어떤 도구를 사용할때 그것의 작동 원리를 알고 사용하는 것과 모른 채 사용하는 것 두 차이는 생각보다 큽니다.
예를 들면 전자레인지가 있습니다. 전자레인지의 작동원리는 간단하게 물분자들을 진동시켜 열을 발생시킵니다. 이러한 원리를 알고 있으면 음식을 데울때 물을 같이 넣어서 음식이 건조해지는걸 방지하는 방법으로 좀 더 맛있게 요리를 할 수 있죠.
이렇게 간단하고 편리해보이는 도구들은 그 작동 원리를 조금이나마 알고 사용하게 될 때 비로소 효율성이 극대화 된다고 생각합니다.
그럼 이제 스테이블 디퓨전이 이미지를 어떻게 만들어내는지 알아보겠습니다.
1. 디퓨전 모델
우리가 스테이블 디퓨전의 작동 원리를 알려면 우선적으로 디퓨전 모델이 무엇인지 대충이나마 알아야 합니다.
디퓨전 모델은 딥러닝 모델의 일종으로 학습 받은 데이터와 비슷한 새로운 데이터를 생성하도록 설계된 모델입니다.
chatGPT는 데이터를 텍스트로 반환하고 스테이블 디퓨전은 데이터를 이미지로 반환하는거죠.
디퓨전은 우리말로 해석하면 '확산'입니다. 앞서 포스팅에서 말했듯이 물리학에서의 확산(diffusion)과 수학적으로 매우 비슷하기 때문입니다.
디퓨전 모델은 이렇게 확산의 원리를 이용한 도구라고 생각하시면 됩니다.
물컵에 잉크를 한방울 떨어뜨리는 것과 비슷하게 보시면 됩니다. 잉크가 물속에서 확산(diffusion)하게 되고, 몇분이 지나면 물속에 완전히 퍼져버려서 처음에 잉크가 어디에 떨어졌는지 전혀 알 수 없게 되어 버립니다.

그렇다면 이 퍼져버린 잉크를 다시 거꾸로 뽑아낼 수 있다면 어떻게 될까요? 현실에서 이미 퍼져버린 잉크는 다시 뽑아낼 수 없지만 데이터 세상에서는 가능합니다. 우리는 이걸 역방향 확산(Reverse diffusion)이라고 합니다.

이 기술이 가능하려면 이미지에 얼마나 많은 잡음이 들어있는지 알아야 합니다. 방법은 신경망(NEURAL NETWORK) 모델에게 추가된 잡음을 예측하도록 학습시키는 것입니다. 이것을 스테이블 디퓨전에서는 잡음 예측기(noise predictor)라고 하며, 이렇게 순방향 확산을 여러번 해서 모델을 학습 시키고 역방향 확산으로 이미지를 생성하는 것입니다. (참고로 스테이블 디퓨전은 U-net이라는 모델을 사용하고 있습니다.)
2. 스테이블 디퓨전의 잠재 확산 모델 그리고 VAE
만약 위에 설명한 로직을 수행하려면 엄청난 시간이 들겁니다. 왜냐하면 이미지 공간은 엄청나게 크기가 크기 때문입니다. 3개의 색채널(R,G,B)이 있는 512x512 짜리 이미지라면, 786,462 차원을 차지합니다. 이미지 하나마다 이 값을 지정해야 하는데 당연히 오래걸릴 수 밖에 없죠.
스테이블 디퓨전은 이러한 문제들을 잠재 확산 모델(latent diffusion model)로 해결 했습니다. 먼저 잠재 공간(latent space)으로 이미지를 압축한 뒤 연산을 시행하는 것입니다. 잠재 공간은 이미지 공간에 비해 48배나 작기때문에 훨씬 연산이 빨라집니다.
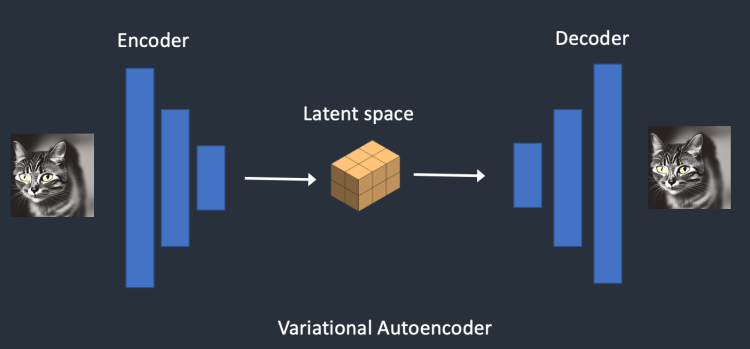
스테이블 디퓨전은 VAE(가변 자동 인코더 Variational AutoEncoder)라는 것을 통해 잠재 공간(Latet spapce)를 통제합니다.
가변 자동 인코더(VAE) 신경망은 (1) 인코더(encoder), (2) 디코더(decoder) 등 두 부분으로 나누어지는데,
인코더는 이미지를 잠재 공간에서 낮은 차원의 표현으로 압축하며, 디코더는 잠재 공간(latent space)으로부터 이미지를 복원하는 역할을 담당합니다.
간단하게 요약하자면 스테이블 디퓨전은 VAE를 통해 고차원 이미지를 압축하고 다시 복원하여 기존 오래 결렸던 디퓨전 모델의 시간을 혁신적으로 단축시킨겁니다.
3.조건부여(Conditioning)
그렇다면 이제 '내가 원하는' 이미지는 어떻게 만들어야 하는 것일까 하는 의문이 생기실 겁니다. 왜냐하면 우리가 아는 이미지 생성형 AI는 텍스트를 작성해 여러 이미지를 만들고 있는데 위 과정에서는 어디에도 텍스트로 제어할 수 있는 공간이 없어 보이기 때문입니다. 우리가 원하는 것은 '우주에서 도지코인을 사용하고 있는 고양이'인데 말이죠.
아래는 텍스트가 처리되어 잡음 예측기로 들어가는 방법을 대략적으로 나타낸 그림입니다.
그림만 봐서는 한번에 이해하기 어려우실 겁니다. 아래 그림을 간단하게 설명해드리겠습니다.
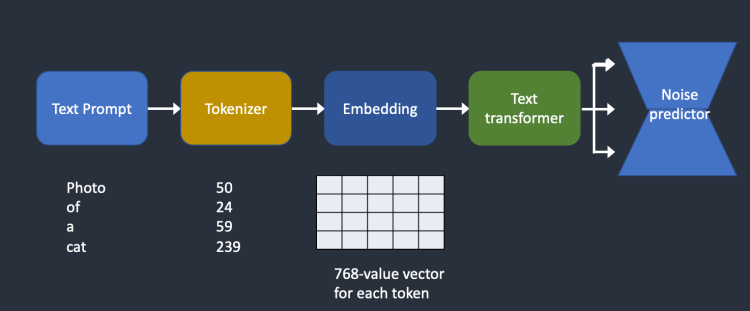
컴퓨터는 영어든 한국어든 텍스트를 있는 그대로 이해할 수 없습니다. 그래서 우리는 이러한 단어들을 숫자로 표현해 컴퓨터가 이해할 수 있게 해줘야 하는데 이것을 토큰생성기(Tokenizer)를 통해 토큰으로 변환시켜주어야 합니다. 이것을 텍스트 인코더(Text Encoder)라고 부르며 스테이블 디퓨전은 Clip이라는 텍스트 인코더를 사용합니다.
이렇게 토큰으로 변한된 값은 임베딩(Embedding)을 거쳐 텍스트 트랜스포머(text transformer)에서 처리된 후 잡음 예측기인 U-net에 공급됩니다. 이 과정을 거쳐야만 텍스트가 온전히 잡음 예측기에 전달 됩니다.
임베딩(Embedding)이란 사람이 쓰는 자연어를 기계가 이해할 수 있는 숫자의 나열인 벡터로 바꾼 결과 혹은 그 과정 전체를 의미합니다
4. 정리
스테이블 디퓨전의 중요 요소를 정리하면서 글을 마무리하도록 하겠습니다.
- 순방향 확산: 물컵에 무작위로 물감(노이즈)을 추가하여 원본 이미지를 흐릿하게 만드는 첫 번째 단계
- 역방향 확산 : 퍼져버린 잉크를 다시 뽑아내는 방법으로 노이즈를 조금씩 제거하여 그 밑에 있는 이미지를 드러내는 단계
- 가변 자동 인코더(VAE): 이 구성 요소는 이미지를 관리하기 쉬운 잠재적 표현으로 변환한 후 필요할 때 디코딩하는 역할을 담당
- 잡음 예측기 U-Net: 이 네트워크는 최종 이미지를 예측하여 세부 사항을 다듬고 텍스트 임베딩을 활용하여 안내 역할을 담당
- 텍스트 인코더: 이 모듈은 입력된 텍스트 프롬프트를 U-Net이 이미지를 생성할 때 안내할 수 있는 형식으로 변환하는 역할을 담당
이렇게 스테이블 디퓨전은 위 요소들을 이용해 이미지를 생성한다고 보시면 되겠습니다. U-net의 작동원리, 임베딩 벡터값 등 더 딥하게 들어갈 수 있지만 최소한으로 원리를 이해한 뒤 이제 실전으로 넘어가보도록 하겠습니다.

'Stable Diffusion > 튜토리얼' 카테고리의 다른 글
| ComfyUI StableDiffusion3 Medium 설치 방법 및 필수 정리 (0) | 2024.06.20 |
|---|---|
| Clip skip(CLIP Set Last Layer)이 도대체 뭘까? (1) | 2024.05.31 |
| Stable Diffusion LoRA 기본 가이드(1) (0) | 2024.05.08 |
| Stable Diffusion을 다루기 위한 프롬프트 작성 기본 가이드 (0) | 2024.05.07 |
| 스테이블 디퓨전(Stable diffusion) 매개변수(parameters) 알아보기 (0) | 2024.04.27 |
생성형 이미지 AI 중 스테이블 디퓨전에 관한 내용을 주로 다룹니다.
포스팅이 좋았다면 "좋아요❤️" 또는 "구독👍🏻" 해주세요!



